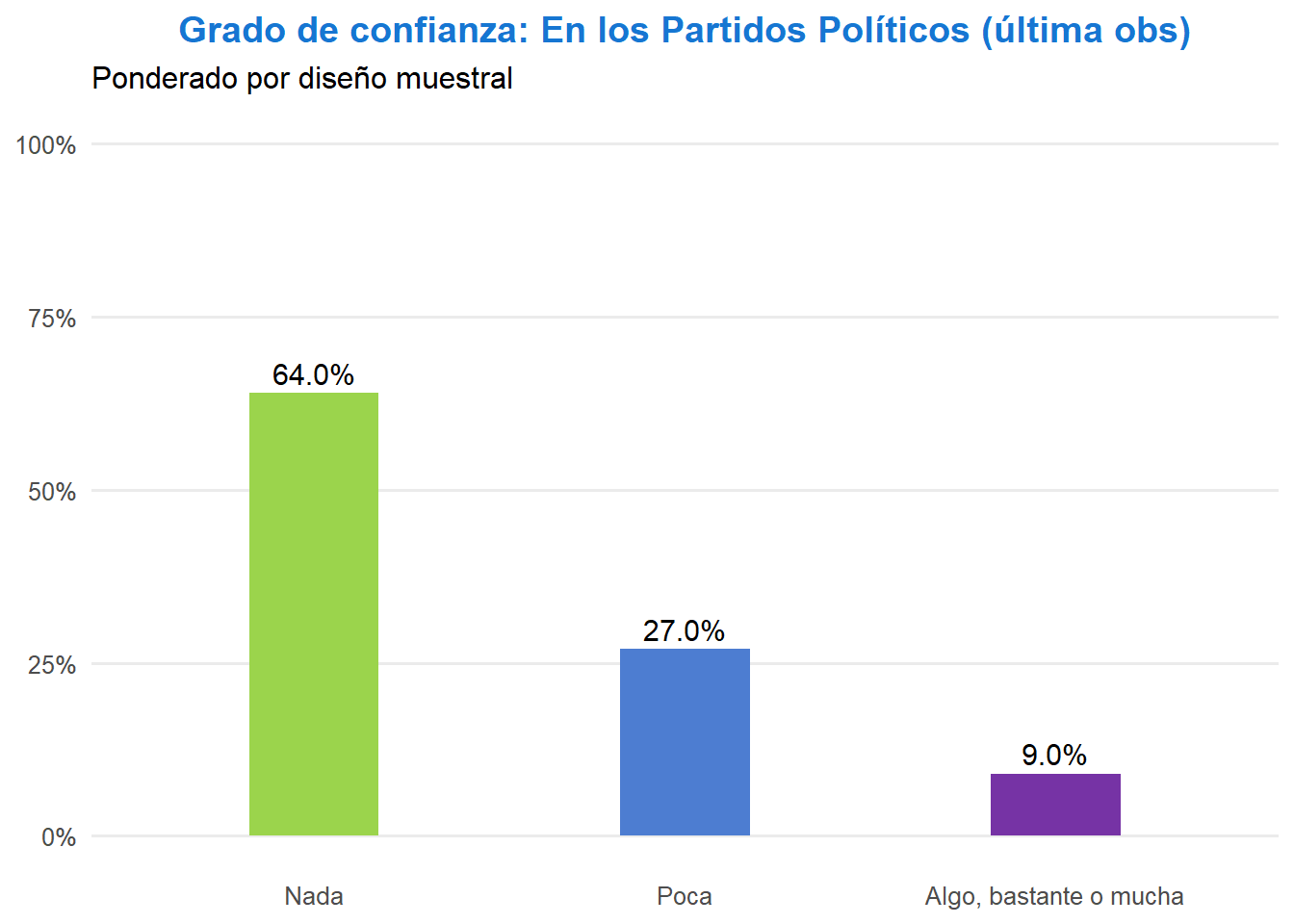
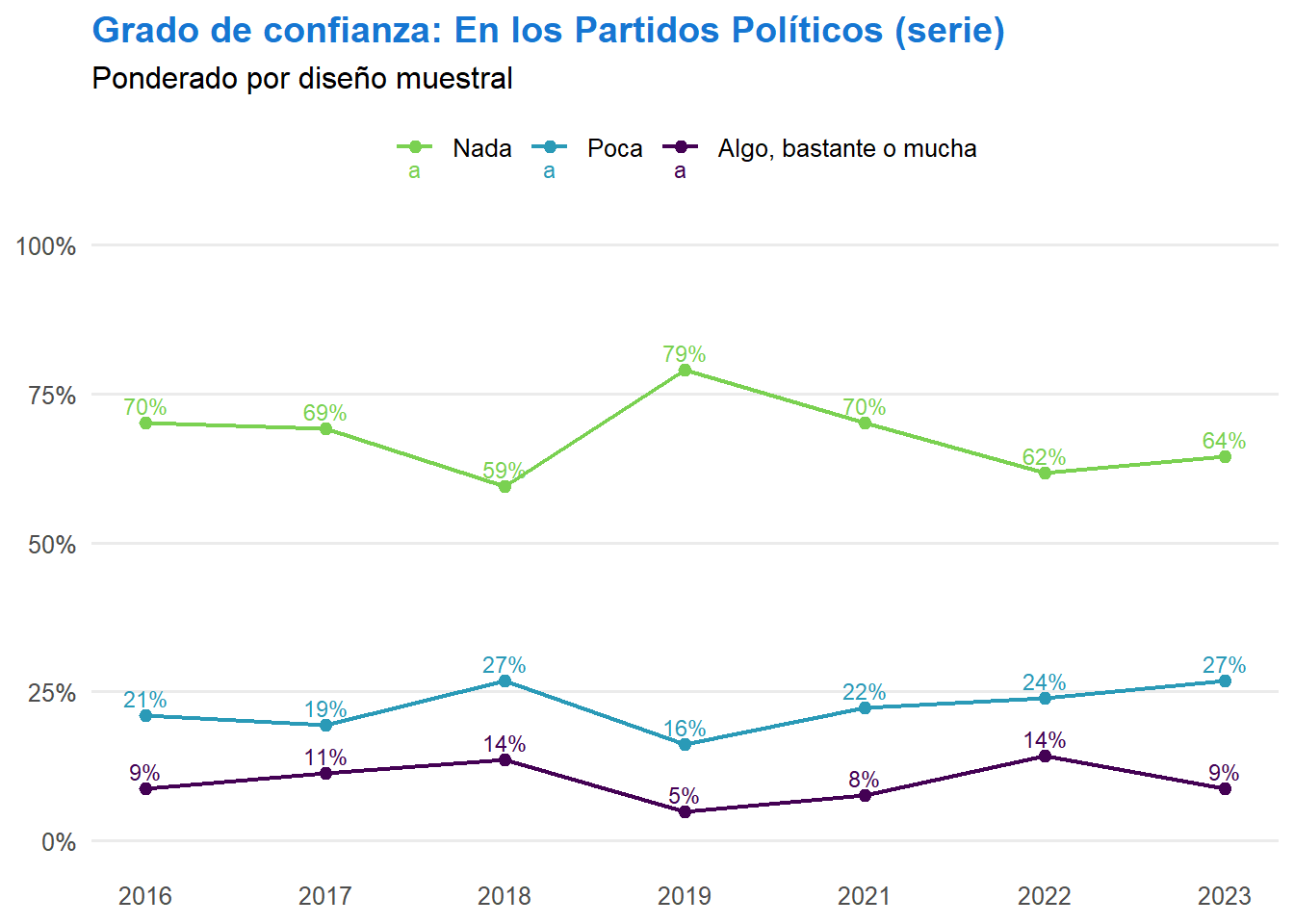
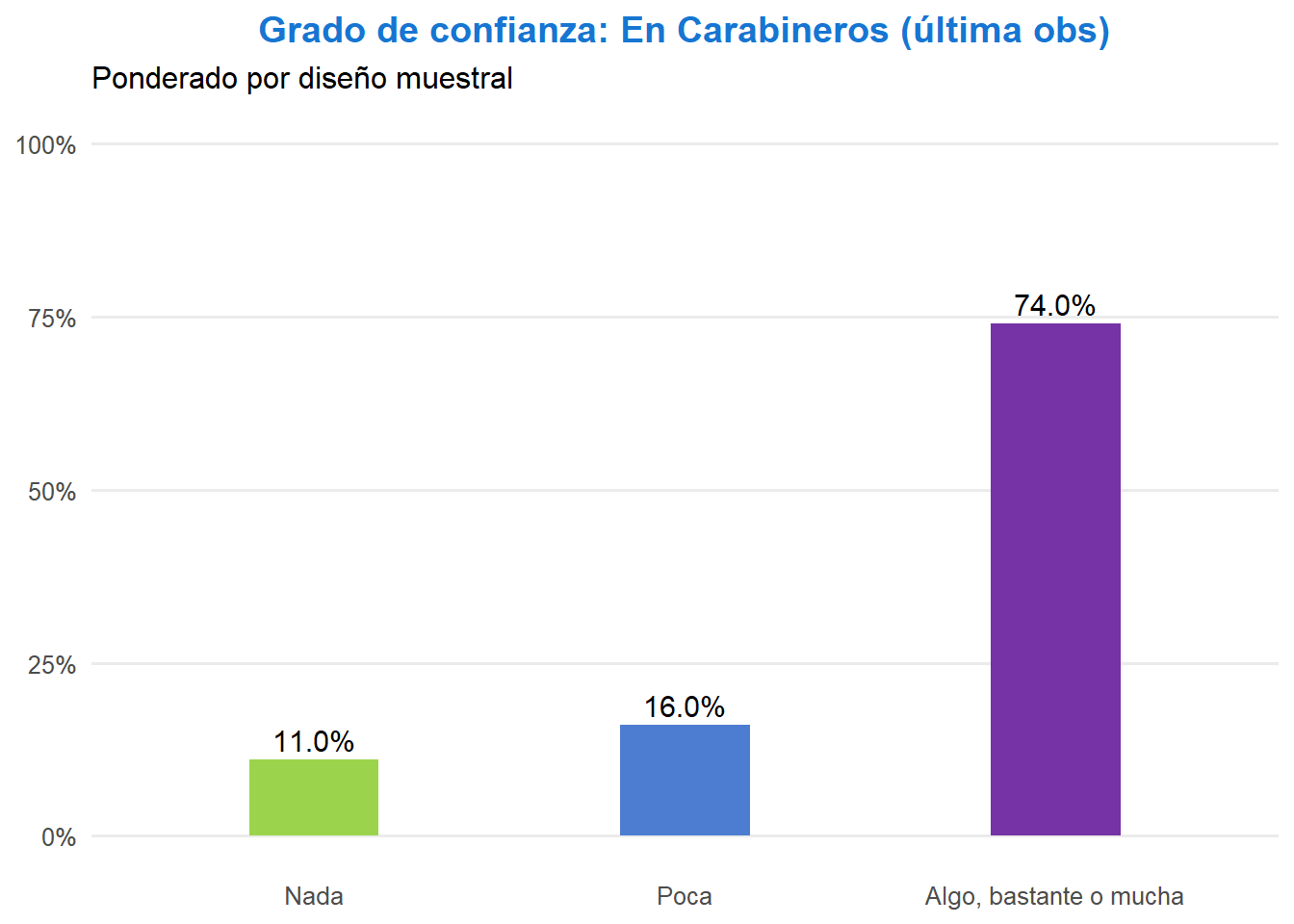
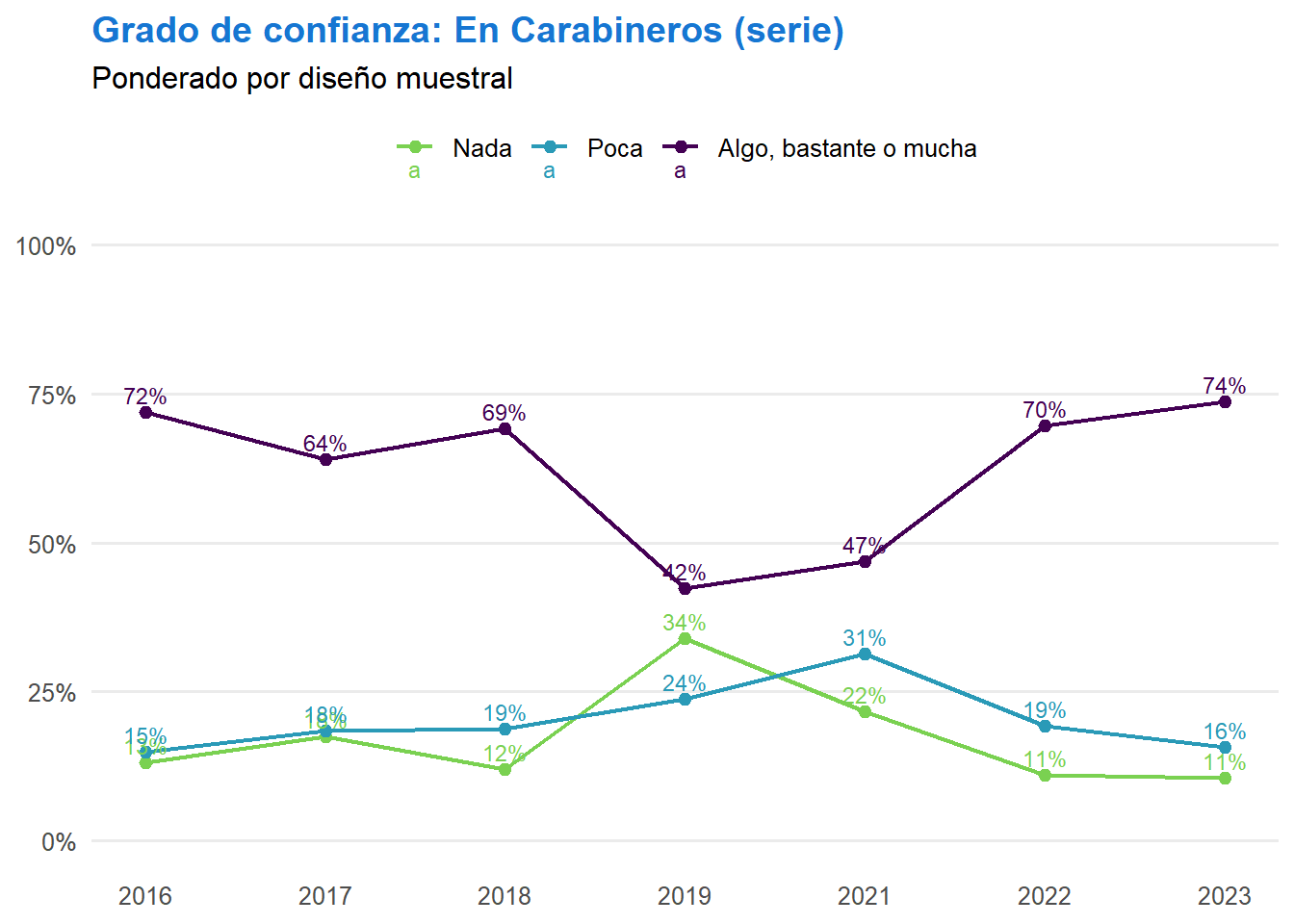
library(survey)
library(ggplot2)
library(tidyverse)
library(ggrepel)
library(sjlabelled)
library(languageserver)
library(Hmisc)
# 1. Cargar base de datos elsoc 2016-2022 para extraer los labels
load("/Users/gustavoahumada/Dropbox/ELSOC2023/tareas/propuesta_RCS2023/bases/ELSOC_Long.RData")
#load("C:/Users/aigon/Dropbox/Proyectos/Datos ELSOC/Datos/ELSOC_Long.RData")
ell <- elsoc_long_2016_2022; elsoc_long_2016_2022 <- NULL
# 1.a. en variables_vector escribir las variables que van a ser usadas para la RCS (incluyendo sociodemograficas
# las que deben estar juntas, idealmente al inicio o al final del vector)
variables_vector <- c("c02", "c03", "t01", "c35_01", "c35_02", "c35_03",
"c35_04", "g01_04", "r09","r12_03","r12_04","r16",
"c32_01", "t02_02", "c05_02", "c05_03","c05_05", "c05_07",
"c18_09", "c04", "c07_02", "c08_02", "c09_04",
"c10_01", "c10_02", "c10_03","c37_05",
"m0_sexo", "m0_edad", "m01", "d01_01", "c15","r05_02",
"r06","r07","r08")
labels_list <- list()
min_values_list <- list()
labels_list_2 <- list()
# 1.b se extraen los labels y otros valores más
for (i in 1:length(variables_vector)) {
vector <- variables_vector[[i]]
vector_labels <- c()
vector_labels_2 <- c()
vector_min_values <- c()
for (var in vector) {
if (var %in% names(ell)) {
vector_labels <- c(vector_labels, Hmisc::label(ell[[var]]))
min_value <- min(ell[[var]][ell[[var]] > 0], na.rm = TRUE)
vector_min_values <- c(vector_min_values, min_value)
vector_labels_2 <- c(vector_labels_2,attr(ell[[var]],"labels"))
}
}
labels_list[[i]] <- vector_labels
names(labels_list)[i] <- vector
min_values_list[[i]] <- vector_min_values
labels_list_2[[i]] <- vector_labels_2
}
labels_list[["c35_01"]] <- "Frecuencia: Trato respetuoso en servicios de salud a clase social subjetiva de la persona"
labels_list[["c35_02"]] <- "Frecuencia: Trato respetuoso en el trabajo a clase social subjetiva de la persona"
labels_list[["c35_03"]] <- "Frecuencia: Trato respetuoso por Carabineros a clase social subjetiva de la persona"
labels_list[["c35_04"]] <- "Frecuencia: Trato respetuoso por personas de clase alta a clase social subjetiva de la peresona"
labels_list[["g01_04"]] <- "Grado de acuerdo: Sexismo hacia las mujeres"
# 2. Cargar base de datos consolidada
ell_23 <- readRDS("/Users/gustavoahumada/Dropbox/ELSOC2023/tareas/propuesta_RCS2023/bases/ELSOC_Long_2016_2023.rds")
load("/Users/gustavoahumada/Dropbox/ELSOC2023/tareas/propuesta_RCS2023/bases/Perfiles.RData")
#load("C:/Users/aigon/Dropbox/ELSOC2023/Otros/Perfiles.RData")
#ell_23 <- readRDS("C:/Users/aigon/Dropbox/ELSOC2023/tareas/propuesta_RCS2023/bases/ELSOC_Long_2016_2023.rds")
# 2.a Hacer las recodificaciones correspondientes
perfiles <- perfiles %>% mutate(pp_3 = factor(pp_3, levels = c("Votante Habitual",
"Votante Reactivo",
"No Votante")))
norte <- c(1,2,15,3,4)
centro <- c(5,6,7,16)
sur <- c(8,9,10,11,12)
rm <- 13
ell_23 <- ell_23 %>% filter(tipo_atricion == 1) %>% left_join(perfiles, by = "idencuesta") %>%
as_label(m0_sexo,estrato) %>%
mutate(across(c(c07_01, c07_02, c07_03, c07_04, c07_05, c07_06, c07_07, c07_08, c08_02, c08_04),
~ifelse(. < 1, 0, .)),
across(c(c02, c03, t01, c35_01, c35_02, c35_03,
c35_04, g01_03, g01_04, r05_02, r06, r07, r08, r09, r12_03, r12_04, r16,
c32_01, t02_02, c05_02, c05_05, c05_07,
c18_09, c04, c07_02, c08_02, c09_04,
c10_01, c10_02, c10_03, c37_05),
~ifelse(. < 1, 0, .)),
m0_sexo = factor(m0_sexo, labels = c("Hombre","Mujer")),
c02_var = factor(car::recode(c02, recodes = "0=0; 1 = 1; 2 = 2; 3 = 3"),
levels = c(0,3,2,1),
labels = c ("NS/NR",
"Depende",
"Casi siempre hay que tener cuidado al tratar con las personas",
"Casi siempre se puede confiar en las personas")),
c03_var = factor(car::recode(c03, recodes = "0=0; 1 = 1; 2 = 2; 3 = 3"),
levels = c(0,3,2,1),
labels = c ("NS/NR","Depende",
"La mayoria de las veces se preocupan solo de si mismas",
"La mayoria de las veces tratan de ayudar a los demas"
)),
c04_var = factor(car::recode(c04, recodes = "0=0; 1 = 1; 2 = 2; 3 = 3"),
levels = c(0,3,1,2),
labels = c ("NS/NR","Depende",
"La mayoria de la gente intentaria aprovecharse",
"La mayoria de la gente trataria de ser justa"
)),
t01_var = factor(car::recode(t01, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Muy poco",
"Poco o algo",
"Bastante o mucho")),
c35_01_var = factor(car::recode(c35_01, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nunca o casi nunca",
"A veces",
"Casi siempre o siempre")),
c35_02_var = factor(car::recode(c35_02, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nunca o casi nunca",
"A veces",
"Casi siempre o siempre")),
c35_03_var = factor(car::recode(c35_03, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nunca o casi nunca",
"A veces",
"Casi siempre o siempre")),
c35_04_var = factor(car::recode(c35_04, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nunca o casi nunca",
"A veces",
"Casi siempre o siempre")),
g01_04_var = factor(car::recode(g01_04, recodes = "0= 0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni de acuerdo ni en desacuerdo",
"De acuerdo o totalmente de acuerdo")),
r09_var = factor(car::recode(r09, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Muy poco o nada",
"Poco o algo",
"Bastante o mucho")),
r12_03_var = factor(car::recode(r12_03, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
r12_04_var = factor(car::recode(r12_04, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
r16_var = factor(car::recode(r16, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nada de confianza o poca confianza",
"Algo de confianza",
"Bastante confianza o mucha confianza")),
c32_01_var = factor(car::recode(c32_01, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
t02_02_var = factor(car::recode(t02_02, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni de acuerdo ni en desacuerdo",
"De acuerdo o totalmente de acuerdo")),
c05_02_var = factor(car::recode(c05_02, recodes = "0= 0; 1 = 1; 2 = 2; 3:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nada",
"Poca",
"Algo, bastante o mucha")),
c05_03_var = factor(car::recode(c05_03, recodes = "0= 0; 1 = 1; 2 = 2; 3:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nada",
"Poca",
"Algo, bastante o mucha")),
c05_05_var = factor(car::recode(c05_05, recodes = "0= 0; 1 = 1; 2 = 2; 3:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nada",
"Poca",
"Algo, bastante o mucha")),
c05_07_var = factor(car::recode(c05_07, recodes = "0= 0; 1 = 1; 2 = 2; 3:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nada",
"Poca",
"Algo, bastante o mucha")),
c18_09_var = factor(car::recode(c18_09, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
c07_02_var = factor(car::recode(c07_02, recodes = "0 = 0; 1 = 1; 2:3 = 2"),
levels = 0:2,
labels = c ("NS/NR","Nunca lo hizo",
"Lo hizo una o más de dos veces")),
c08_02_var = factor(car::recode(c08_02, recodes = "0 = 0; 1 = 1; 2 = 2; 3:5 = 3"),
levels = 0:3,
labels = c("NS/NR",
"Nunca", "Casi nunca",
"A veces, frecuentemente o muy frecuentemente")),
c09_04_var = factor(car::recode(c09_04, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nada o casi nada dispuesto",
"Algo dispuesto",
"Bastante o totalmente dispuesto")),
c10_01_var = factor(car::recode(c10_01, recodes = "0 = 0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
c10_02_var = factor(car::recode(c10_02, recodes = "0 = 0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
c10_03_var = factor(car::recode(c10_03, recodes = "0 = 0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
c37_05_var = factor(car::recode(c37_05, recodes = "0 = 0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Totalmente en desacuerdo o en desacuerdo",
"Ni en desacuerdo ni de acuerdo",
"De acuerdo o totalmente de acuerdo")),
estrato_rec = factor(case_when(
estrato %in% c("Gran Santiago","Gran Valparaiso","Gran Concepcion","Ciudades Grandes (+ 100.000 hab)") ~ "Ciudades Grandes (+ 100.000 hab)",
estrato == "Ciudades Medianas" ~ "Ciudades Medianas (+ 30.000 hab)",
estrato == "Ciudades Pequennias" ~ "Ciudades Pequeñas (+ 10.000 hab)")),
zona_rec = factor(case_when(
region_cod %in% norte ~ "Norte",
region_cod %in% centro ~ "Centro",
region_cod %in% sur ~ "Sur",
region_cod %in% rm ~ "RM"
)),
zona_rec_var = factor(case_when(
region_cod %in% norte ~ "Norte",
region_cod %in% centro ~ "Centro",
region_cod %in% sur ~ "Sur",
region_cod %in% rm ~ "RM"
))
)
# calculo promedio variables
ell_23 <- ell_23 %>%
mutate(across(c(c07_01, c07_02, c07_04, c07_05, c07_06, c07_07, c07_08, c08_02)),
across(c(t11_01, t11_02, t11_04)), across(c(g01_03, g01_04))) %>% rowwise() %>%
mutate(promedio_solidaridad = mean(c(c07_01, c07_02, c07_04, c07_05, c07_06, c07_07, c07_08),
na.rm = TRUE)) %>%
mutate(promedio_solidaridad = round(promedio_solidaridad)) %>%
mutate(promedio_solidaridad = factor(car::recode(promedio_solidaridad, "0 = 0 ; 1 = 1; 2:3 = 2"),
levels = 0:2,
labels = c("NS/NR" , "Nunca lo hizo", "Lo hizo una o más de dos veces"))) %>%
mutate(sdd_primaria = mean(c(c07_01, c07_03),na.rm = TRUE)) %>%
mutate(sdd_primaria = round(sdd_primaria)) %>%
mutate(sdd_primaria = factor(car::recode(sdd_primaria, "0 = 0 ; 1 = 1; 2:3 = 2"),
levels = 0:2,
labels = c("NS/NR" , "Nunca lo hizo", "Lo hizo una o más de dos veces"))) %>%
mutate(pro_soc = mean(c(c07_02, c07_04, c07_05),na.rm=TRUE)) %>%
mutate(pro_soc = round(pro_soc)) %>%
mutate(pro_soc = factor(car::recode(pro_soc, "0 = 0 ; 1 = 1; 2:3 = 2"),
levels = 0:2,
labels = c("NS/NR" , "Nunca lo hizo", "Lo hizo una o más de dos veces"))) %>%
mutate(apoyo_soc = mean(c(c07_06, c07_07, c07_08),na.rm=TRUE)) %>%
mutate(apoyo_soc = round(apoyo_soc)) %>%
mutate(apoyo_soc = factor(car::recode(apoyo_soc, "0 = 0 ; 1 = 1; 2:3 = 2"),
levels = 0:2,
labels = c("NS/NR" , "Nunca lo hizo", "Lo hizo una o más de dos veces"))) %>%
mutate(sexismo = mean(c(g01_03,g01_04),na.rm=T)) %>%
mutate(sexismo = round(sexismo)) %>%
mutate(sexismo = factor(car::recode(sexismo, "0 = 0 ; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR" , "Bajo nivel", "Nivel medio","Alto nivel")))
# 2.b a los promedios se les da un label (aunque es un paso que puede saltarse)
Hmisc::label(ell_23$promedio_solidaridad) <- "Promedio de Comportamiento Pro-Social"
Hmisc::label(ell_23$sdd_primaria) <- "Promedio de Sociabilidad Primaria"
Hmisc::label(ell_23$pro_soc) <- "Promedio de Comportamiento Pro-social"
Hmisc::label(ell_23$apoyo_soc) <- "Promedio de Apoyo Social"
Hmisc::label(ell_23$sexismo) <- "Promedio de sexismo"
# ajustar variables
ell_23 <- ell_23 %>%
mutate(c15 = replace(c15, c15 < 0, -1),
m01 = replace(m01, m01 < 0, 0),
c33 = replace (c33, c33 < 0, 0),
d01_01 = replace(d01_01, d01_01 < 0, -1),
t09_02 = replace(t09_02, t09_02 < 0, 0),
t10 = replace(t10, t10 < 0, 0))
ell_23 <- ell_23 %>%
mutate(c15_nf = factor(car::recode(c15, recodes = "-1 = 0; 0:4 = 1; 5 = 2; 6:10 = 3; 11:12 = 4"),
levels = 0:4,
labels = c("NS/NR", "Izquierda", "Centro", "Derecha", "Independiente/Ninguno")),
educ_nf = factor(car::recode(m01, recodes = "0=0 ; 1:3 = 1; 4:5 = 2; 6:7 = 3; 8:10 = 4"),
levels = 0:4,
labels = c("NS/NR", "Básica", "Media", "Técnica", "Universitaria")),
clase_nf = factor(car::recode(c33, recodes = "0 = 0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR", "Clase baja", "Clase media", "Clase alta")),
clase_nf2 = factor(car::recode(d01_01, recodes = "-1 = 0; 0:3 = 1; 4:6 = 2; 7:10 = 3"),
levels = 0:3,
labels = c("NS/NR", "Clase baja", "Clase media", "Clase alta")),
edad_nf = factor(car::recode(m0_edad, "18:29 = 1; 30:49 = 2; 50:64 = 3; 65:150 = 4"),
levels = 1:4,
labels = c("18-29 años", "30-49 años", "50-64 años", "65 o más años")),
cont_mig_nf = factor(car::recode(r05_02, recodes = "0= 0; 1 = 1; 2:5 = 2"),
levels = 0:2,
labels = c("NS/NR","Ninguno",
"Algunos, bastantes o muchos")),
frec_cont_nf = factor(car::recode(r06, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR",
"Baja frecuencia de contacto",
"Mediana frecuencia de contacto",
"Alta frecuencia de contacto")),
cont_pos_nf = factor(car::recode(r07, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR",
"Muy poco amistosa o Poco amistosa",
"Ni amistosa ni no amistosa",
"Bastante amistosa o muy amistosa")),
frec_cont_neg_nf = factor(car::recode(r08, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR",
"Baja frecuencia de contacto negativo",
"Mediana frecuencia de contacto negativo",
"Alta frecuencia de contacto negativo"))
)
# asignacion escala izquierda-derecha
rango_conteo <- ell_23 %>%
group_by(idencuesta) %>%
summarise(
count_1 = sum(c15 == -1, na.rm = TRUE),
count_0_4 = sum(c15 %in% c(0:4), na.rm = TRUE),
count_5 = sum(c15 == 5, na.rm = TRUE),
count_6_10 = sum(c15 %in% c(6:10), na.rm = TRUE),
count_11 = sum(c15 == 11, na.rm = TRUE),
count_12 = sum(c15 == 12, na.rm = TRUE),
)
ell_23 <- ell_23 %>%
left_join(rango_conteo, by = "idencuesta") %>%
mutate(
c15 = case_when(
count_1 >= 4 ~ 0,
count_0_4 >= 4 ~ 1,
count_5 >= 4 ~ 2,
count_6_10 >= 4 ~ 3,
count_11 >= 4 ~ 4,
count_12 >= 4 ~ 5,
TRUE ~ 4
))
# asignacion variables a ano base (2018) o promedio
ell_23 <- ell_23 %>%
group_by(idencuesta) %>%
mutate(m0_edad = ifelse(any(ola == 3), m0_edad[ola == 3], NA),
educ = ifelse(any(ola == 3), m01[ola == 3], NA),
clase = mean(c33, na.rm = TRUE),
c33 = ifelse(any(ola == 3), c33[ola == 3], NA),
d01_01 = ifelse(any(ola == 3), d01_01[ola == 3], NA),
r16 = ifelse(any(ola == 4), r16[ola == 4], NA),
r05_02 = ifelse(any(ola == 3), r05_02[ola == 3], NA),
r06 = ifelse(any(ola == 3), r06[ola == 3], NA),
r07 = ifelse(any(ola == 3), r07[ola == 3], NA),
r08 = ifelse(any(ola == 3), r08[ola == 3], NA),
t09_02 = ifelse(any(ola == 3), t09_02[ola == 3], NA),
t10 = ifelse(any(ola == 3), t10[ola == 3], NA),
zona_rec = ifelse(any(ola == 3), zona_rec[ola == 3], NA)) %>%
ungroup()
# recodificar variables
ell_23 <- ell_23 %>%
mutate(c15 = factor(car::recode(c15, recodes = "1 = 1; 2 = 2; 3 = 3; 4:5 = 4"),
levels = 1:4,
labels = c("Izquierda", "Centro", "Derecha", "Independiente/Ninguno")),
educ = factor(car::recode(educ, recodes = "0 = 0; 1:3 = 1; 4:5 = 2; 6:7 = 3; 8:10 = 4"),
levels = 0:4,
labels = c("NS/NR", "Básica", "Media", "Técnica", "Universitaria")),
c33 = factor(car::recode(c33, recodes = "0 = 0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR", "Clase baja", "Clase media", "Clase alta")),
clase = factor(car::recode(clase, recodes = "0 = 0; 1:2.5 = 1; 2.75:3.5 = 2; 3.75:5 = 3"),
levels = 0:3,
labels = c("NS/NR", "Clase baja", "Clase media", "Clase alta")),
d01_01 = factor(car::recode(d01_01, recodes = "-1 = 0; 0:3 = 1; 4:6 = 2; 7:10 = 3"),
levels = 0:3,
labels = c("NS/NR", "Clase baja", "Clase media", "Clase alta")),
m0_edad = factor(car::recode(m0_edad, "18:29 = 1; 30:49 = 2; 50:64 = 3; 65:150 = 4"),
levels = 1:4,
labels = c("18-29 años", "30-49 años", "50-64 años", "65 o más años")),
r16 = factor(car::recode(r16, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nada de confianza o poca confianza",
"Algo de confianza",
"Bastante confianza o mucha confianza")),
r05_02 = factor(car::recode(r05_02, recodes = "0= 0; 1 = 1; 2:5 = 2"),
levels = 0:2,
labels = c("NS/NR","Ninguno",
"Algunos, bastantes o muchos")),
r06 = factor(car::recode(r06, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR",
"Alta frecuencia de contacto",
"Mediana frecuencia de contacto",
"Baja frecuencia de contacto")),
r07 = factor(car::recode(r07, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Muy poco amistosa o Poco amistosa",
"Ni amistosa ni no amistosa",
"Bastante amistosa o muy amistosa")),
r08 = factor(car::recode(r08, recodes = "0=0; 1 = 1; 2:3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR",
"Alta frecuencia de contacto negativo",
"Mediana frecuencia de contacto negativo",
"Baja frecuencia de contacto negativo")),
t09_02 = factor(car::recode(t09_02, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Nunca o pocas veces",
"Algunas veces",
"Muchas veces o siempre")),
t10 = factor(car::recode(t10, recodes = "0=0; 1:2 = 1; 3 = 2; 4:5 = 3"),
levels = 0:3,
labels = c("NS/NR","Muy inseguro o inseguro",
"Ni seguro ni inseguro",
"Seguro o muy seguro")),
zona_rec = factor(car::recode(zona_rec, recodes = "1 = 1; 2 = 2; 3 = 3; 4 = 4"),
levels = 1:4,
labels = c("Norte",
"Centro",
"Sur", "RM"))
)
ell_23 <- ell_23 %>%
mutate(
ola = case_when(
ola == 1 ~ 2016,
ola == 2 ~ 2017,
ola == 3 ~ 2018,
ola == 4 ~ 2019,
ola == 5 ~ 2021,
ola == 6 ~ 2022,
ola == 7 ~ 2023
)
)
cor(with(ell_23,cbind(g01_03,g01_04)),use="complete.obs")
library(psych)
alpha(with(ell_23,cbind(g01_03,g01_04)))
aux <- ell_23 %>%
select(c05_03, c35_03) %>%
filter(c05_03 != "NS/NR", c35_03 != "NS/NR") %>%
mutate(across(everything(), as.numeric))
aux <- ell %>% select(c05_03, c35_03) %>%
filter(c05_03 > 0, c35_03 > 0)
cor(aux)
# 3. pasar base de datos consolidada a formato svy()
ell.svy <- svydesign(ids = ~segmento_disenno,weights = ~ponderador02,
data = ell_23,nest = TRUE,strata = ~estrato_disenno)
# 4. se crean vectores con las variables que van a ser usadas para la RCS
# 4.a. El primer vector llamado variables debe ir hasta la primera variable sociodemografica, en este caso m0_sexo
variables <- variables_vector[1:which(variables_vector=="m0_sexo")-1]
# 4.b. se renombran los vectores de la manera en la cual fueron recodificados (a todos menos a t11_01 se les añade _var)
variables <- ifelse(variables != "t11_01",paste(variables,"var",sep="_"),variables)
# 4.c se añade la variable creada llamada promedio_solidaridad
variables <- c("sdd_primaria","pro_soc","apoyo_soc","sexismo",variables)
variables_sd <- c("m0_sexo","edad_nf","educ_nf","clase_nf2","c15_nf","cont_mig_nf",
"frec_cont_nf","cont_pos_nf","frec_cont_neg_nf") # Para graficar las variables sociodemograficas sin fijar
# 4.d se crea un vector con las variables sociodemograficas fijadas, y se crea un segundo vector llamado combined_vars donde se
# combinan todas las variables junto con el signo +
variables_cruce <- c("m0_sexo","m0_edad","educ","d01_01","c15","pp_3",
"t09_02", "t10", "zona_rec", "cont_mig_nf",
"frec_cont_nf","cont_pos_nf","frec_cont_neg_nf") # Para hacer los cruces con las variables sociodemogarficas fijadas
combined_vars <- as.vector(outer(variables, variables_cruce[1:9], paste, sep = "+"))
combined_vars <- c(combined_vars,as.vector(outer(c("r09_var","r12_03_var",
"r12_04_var","r16_var","c37_05_var"),
c("cont_mig_nf",
"frec_cont_nf","cont_pos_nf",
"frec_cont_neg_nf"),paste,sep="+")))
# Se crean listas para guardar los graficos
graficos <- list()
graficos_sd <- list()
graficos_cruces <- list()
titulos <- c(label(ell_23$sdd_primaria)[1],label(ell_23$pro_soc)[1],
label(ell_23$apoyo_soc)[1],label(ell_23$sexismo)[1],
unlist(labels_list)[1:27])
titulos_sd <- unlist(labels_list)[28:36] # Hay que agregar titulo para el perfil de votantes
# Si es que se quiere graficar a lo largo del tiempo
# Se calculan los graficos
for (i in 1:length(variables)){
var <- variables[i]
t <- as.data.frame(svytable(as.formula(paste("~", var, "+ ola")), design=ell.svy))
t <- t %>% group_by(ola) %>% mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>%
ungroup() %>% filter(get(var) != "NS/NR") %>% drop_na(prop)
grafico <- ggplot(t,aes(x = ola, y = prop,color= .data[[var]],
group = .data[[var]],
label = scales::percent(prop, accuracy = .1))) +
theme_bw() +
geom_point(size = 1.75) +
geom_line(linewidth=1) +
scale_y_continuous(labels = scales::percent,limits = c(0, 1)) +
ylab(label = NULL) +
xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis',direction = -1) +
geom_text_repel(size = 4, nudge_y = .01) +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10,
face = "bold"), # Tamaño de letra para el eje x
axis.text.y = element_text(size = 10,
face = "bold"),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
ggtitle(titulos[i], subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
if(i == length(variables)){
for(j in 1:length(variables_sd)){
var_sd <- variables_sd[j]
t_sd <- as.data.frame(svytable(as.formula(paste("~", var_sd, "+ ola")), design=ell.svy))
t_sd <- t_sd %>% group_by(ola) %>% mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>%
ungroup() %>% filter(get(var_sd) != "NS/NR") %>% drop_na(prop)
grafico_sd <- ggplot(t_sd,aes(x = ola, y = prop,color= .data[[var_sd]],
group = .data[[var_sd]],
label = scales::percent(prop, accuracy = .1))) +
theme_bw() +
geom_point(size = 1.75) +
geom_line(linewidth=1) +
scale_y_continuous(labels = scales::percent,limits = c(0, 1)) +
ylab(label = NULL) +
xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
geom_text_repel(size = 4, nudge_y = .01) +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10,
face = "bold"), # Tamaño de letra para el eje x
axis.text.y = element_text(size = 10,
face = "bold"),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
ggtitle(titulos_sd[j], subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
graficos_sd[[j]] <- grafico_sd
names(graficos_sd)[j] <- var_sd
}
}
graficos[[i]] <- grafico
names(graficos)[i] <- var
}
# 5. se multiplican los titulos de los graficos según la cantidad de variables de cruce (sociodemograficas)
titulos_rep <- rep(titulos,length(variables_cruce[1:9]))
titulos_rep <- c(titulos_rep,rep(unlist(labels_list)[c(9:12,27)],4))
# 6. se crea un vector para poder filtrar las categorias de los cruces que interesan ser graficadas,
# en este vector pueden sobrar categorias, pero no pueden faltar dado que de lo contrario el grafico no se calculará
categorias_grafico <- c("Lo hizo una o más de dos veces", # Comportamiento prosocial
"Casi siempre se puede confiar en las personas", # Confianza social 1
"La mayoria de las veces tratan de ayudar a los demas", # Confianza social 2
"La mayoria de la gente trataria de ser justa", # Confianza social 3
"Bastante o mucho",
"De acuerdo o totalmente de acuerdo",
"De acuerdo o Totalmente de acuerdo",
"Lo hizo una o más de dos veces",
"Bastante o totalmente dispuesto",
"Siempre o muchas veces",
"Algo, bastante o mucha",
"Algunos, bastantes o muchos",
"Bastante amistosa o muy amistosa",
"Bastante confianza o mucha confianza",
"A veces, frecuentemente o muy frecuentemente",
"Casi siempre o siempre",
"Bastantes o muchos",
"Algunos, bastantes o muchos",
"Bastante o mucho",
"Alta frecuencia",
"Alto nivel")
# Se calculan los graficos de cruce
t_cruce <- as.data.frame(svytable(~sexismo+educ+ola, design=ell.svy))
variable_cruce <- colnames(t_cruce[2])
variable <- colnames(t_cruce[1])
t_cruce <- t_cruce %>% group_by(ola, .data[[variable_cruce]]) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>%
ungroup() %>% arrange(ola) %>% filter(.data[[variable]] != "NS/NR") %>%
filter(.data[[variable_cruce]] != "NS/NR") %>%
filter(.data[[variable]] %in% categorias_grafico)
ggplot(t_cruce,aes(y=prop,x=ola,color=.data[[variable]],
group=.data[[variable]],
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_point(size = 1.75) +
geom_line(linewidth = 1) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
facet_wrap(as.formula(paste("~", variable_cruce))) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
geom_text_repel(size = 4, nudge_y = .01) +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10,
face = "bold"), # Tamaño de letra para el eje x
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12))
for (j in 1:length(combined_vars)){
c_vars <- combined_vars[j]
t_cruce <- as.data.frame(svytable(as.formula(paste("~",c_vars,"+ola")),
design = ell.svy))
variable_cruce <- colnames(t_cruce[2])
variable <- colnames(t_cruce[1])
t_cruce <- t_cruce %>% group_by(ola, .data[[variable_cruce]]) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>%
ungroup() %>% arrange(ola) %>% filter(.data[[variable]] != "NS/NR") %>%
filter(.data[[variable_cruce]] != "NS/NR")
t_cruce <- t_cruce %>% drop_na(prop) %>% filter(.data[[variable]] %in% categorias_grafico)
grafico_cruce <- ggplot(t_cruce,aes(y=prop,x=ola,color=.data[[variable]],
group=.data[[variable]],
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_point(size = 1.75) +
geom_line(linewidth = 1) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
facet_wrap(as.formula(paste("~", variable_cruce))) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
geom_text_repel(size = 4, nudge_y = .01) +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10,
face = "bold"), # Tamaño de letra para el eje x
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
ggtitle(titulos_rep[j], subtitle = 'Porcentaje que responde...') +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).')
graficos_cruces[[j]] <- grafico_cruce
names(graficos_cruces)[j] <- paste(variable_cruce,variable,sep="_")
}
t <- as.data.frame(svytable(~pp_3,design = ell.svy))
t <- t %>% mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>% drop_na(prop) %>%
ggplot(.,aes(x=pp_3,y=prop,color=pp_3,fill=pp_3,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_bar(stat="identity") +
scale_y_continuous(labels = scales::percent,limits = c(0,1)) +
geom_col(position = 'dodge') +
geom_text(position = position_dodge(width = .9), # move to center of bars
vjust = -0.5,size = 4) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
scale_fill_viridis_d(begin = .0, end = .8, option = 'viridis') +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10,
face = "bold"), # Tamaño de letra para el eje x
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
ggtitle("Tipo de votante") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).')
t
graficos_sd[[10]] <- t
names(graficos_sd)[10] <- "pp_3"
t <- as.data.frame(svytable(~c15_nf + ola, design=ell.svy))
t <- t %>% group_by(ola) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>% drop_na(prop) %>%
filter(c15_nf != "NS/NR") %>%
ggplot(.,aes(x=ola,y=prop,color=c15_nf,fill=c15_nf,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_bar(stat = "identity",
aes(fill=c15_nf,color=c15_nf)) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis',direction =1) +
scale_fill_viridis_d(begin = .0, end = .8, option = 'viridis',direction=1) +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10, face = "bold"),
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
geom_text(data = function(x) { group_by(.data = x, ola, c15_nf) %>%
summarise(prop = sum(prop, na.rm = TRUE), idencuesta = 1) %>%
ungroup()},
aes(label = scales::percent(prop, accuracy = .1)),
position = position_stack(vjust = .5),
show.legend = FALSE,
size = 4,
color = rep(c('white', 'white','black','black'),7)) +
ggtitle("Identificación Ideológica",
subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
graficos_sd[[11]] <- t
names(graficos_sd)[11] <- "c15_nf_bar"
# Sexo "","","","","c15_nf"
t <- as.data.frame(svytable(~m0_sexo + ola, design=ell.svy))
t <- t %>% group_by(ola) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>% drop_na(prop) %>%
filter(m0_sexo != "NS/NR") %>%
ggplot(.,aes(x=ola,y=prop,color=m0_sexo,fill=m0_sexo,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_bar(stat = "identity",
aes(fill=m0_sexo,color=m0_sexo)) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
scale_fill_viridis_d(begin = .0, end = .8, option = 'viridis') +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10, face = "bold"),
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
geom_text(data = function(x) { group_by(.data = x, ola, m0_sexo) %>%
summarise(prop = sum(prop, na.rm = TRUE), idencuesta = 1) %>%
ungroup()},
aes(label = scales::percent(prop, accuracy = .1)),
position = position_stack(vjust = .5),
show.legend = FALSE,
size = 4,
color = rep(c('white','black'),7)) +
ggtitle("Sexo del entrevistado",
subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
graficos_sd[[length(graficos_sd)+1]] <- t
names(graficos_sd)[length(graficos_sd)] <- "sexo_nf_bar"
# EDAD
t <- as.data.frame(svytable(~edad_nf + ola, design=ell.svy))
t <- t %>% group_by(ola) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>% drop_na(prop) %>%
filter(edad_nf != "NS/NR") %>%
ggplot(.,aes(x=ola,y=prop,color=edad_nf,fill=edad_nf,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_bar(stat = "identity",
aes(fill=edad_nf,color=edad_nf)) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
scale_fill_viridis_d(begin = .0, end = .8, option = 'viridis') +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10, face = "bold"),
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
geom_text(data = function(x) { group_by(.data = x, ola, edad_nf) %>%
summarise(prop = sum(prop, na.rm = TRUE), idencuesta = 1) %>%
ungroup()},
aes(label = scales::percent(prop, accuracy = .1)),
position = position_stack(vjust = .5),
show.legend = FALSE,
size = 4,
color = rep(c('white','white','black','black'),7)) +
ggtitle("Edad del entrevistado",
subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
graficos_sd[[length(graficos_sd)+1]] <- t
names(graficos_sd)[length(graficos_sd)] <- "edad_nf_bar"
# EDUCACION
t <- as.data.frame(svytable(~educ_nf + ola, design=ell.svy))
t <- t %>% group_by(ola) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>% drop_na(prop) %>%
filter(educ_nf != "NS/NR") %>%
ggplot(.,aes(x=ola,y=prop,color=educ_nf,fill=educ_nf,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_bar(stat = "identity",
aes(fill=educ_nf,color=educ_nf)) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1.01)) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
scale_fill_viridis_d(begin = .0, end = .8, option = 'viridis') +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10, face = "bold"),
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
geom_text(data = function(x) { group_by(.data = x, ola, educ_nf) %>%
summarise(prop = sum(prop, na.rm = TRUE), idencuesta = 1) %>%
ungroup()},
aes(label = scales::percent(prop, accuracy = .1)),
position = position_stack(vjust = .5),
show.legend = FALSE,
size = 4,
color = rep(c('white','white','black','black'),7)) +
ggtitle("Educación del entrevistado",
subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
graficos_sd[[length(graficos_sd)+1]] <- t
names(graficos_sd)[length(graficos_sd)] <- "educacion_nf_bar"
# EDUCACION
t <- as.data.frame(svytable(~clase_nf2 + ola, design=ell.svy))
t <- t %>% group_by(ola) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>% drop_na(prop) %>%
filter(clase_nf2 != "NS/NR") %>%
ggplot(.,aes(x=ola,y=prop,color=clase_nf2,fill=clase_nf2,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_bar(stat = "identity",
aes(fill=clase_nf2,color=clase_nf2)) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
scale_fill_viridis_d(begin = .0, end = .8, option = 'viridis') +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10, face = "bold"),
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
geom_text(data = function(x) { group_by(.data = x, ola, clase_nf2) %>%
summarise(prop = sum(prop, na.rm = TRUE), idencuesta = 1) %>%
ungroup()},
aes(label = scales::percent(prop, accuracy = .1)),
position = position_stack(vjust = .5),
show.legend = FALSE,
size = 4,
color = rep(c('white','white','black'),7)) +
ggtitle("Clase social subjetiva del entrevistado",
subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
graficos_sd[[length(graficos_sd)+1]] <- t
names(graficos_sd)[length(graficos_sd)] <- "clase_nf_bar"
# ZONA
t <- as.data.frame(svytable(~zona_rec_var + ola, design=ell.svy))
t <- t %>% group_by(ola) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2),
zona_rec_var = factor(zona_rec_var,levels = c("Norte","Centro","Sur","RM"))) %>%
drop_na(prop) %>%
filter(zona_rec_var != "NS/NR") %>%
ggplot(.,aes(x=ola,y=prop,color=zona_rec_var,fill=zona_rec_var,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_bar(stat = "identity",
aes(fill=zona_rec_var,color=zona_rec_var)) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1.01)) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis') +
scale_fill_viridis_d(begin = .0, end = .8, option = 'viridis') +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10, face = "bold"),
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
geom_text(data = function(x) { group_by(.data = x, ola, zona_rec_var) %>%
summarise(prop = sum(prop, na.rm = TRUE), idencuesta = 1) %>%
ungroup()},
aes(label = scales::percent(prop, accuracy = .1)),
position = position_stack(vjust = .5),
show.legend = FALSE,
size = 4,
color = rep(c('white','white','black','black'),7)) +
ggtitle("Zona geografica del entrevistado",
subtitle = "Porcentaje que responde...") +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).\nNo se grafican las categorías NS/NR.')
t
graficos_sd[[length(graficos_sd)+1]] <- t
names(graficos_sd)[length(graficos_sd)] <- "zona_nf_bar"
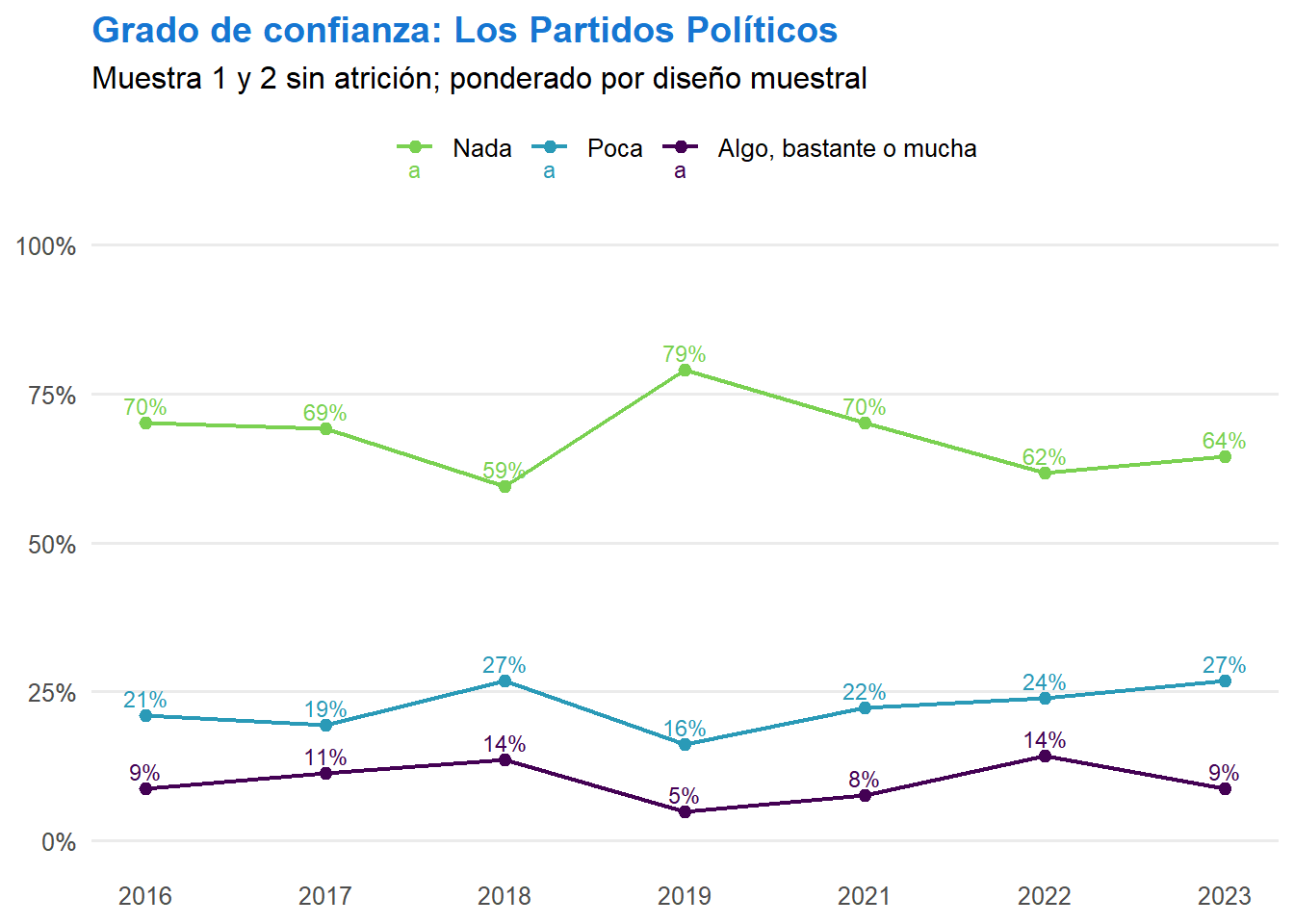
t <- as.data.frame(svytable(~c05_03_var+c35_03_var+ola,
design = ell.svy))
t <- t %>% group_by(ola,c35_03_var) %>%
mutate(prop = round(Freq/sum(Freq,na.rm=T),2)) %>%
ungroup() %>% arrange(ola) %>% filter(c05_03_var != "NS/NR") %>%
filter(c35_03_var != "NS/NR") %>%
filter(c05_03_var %in% categorias_grafico) %>%
mutate(c35_03_var = factor(c35_03_var,labels=c("Nunca o casi nunca \ntrato justo",
"A veces \ntrato justo",
"Siempre o casi siempre \ntrato justo"))) %>%
ggplot(.,aes(y=prop,x=ola,color=c05_03_var,
group=c05_03_var,
label=scales::percent(prop,accuarcy=.1))) +
theme_bw() +
geom_point(size = 1.75) +
geom_line(linewidth = 1) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
facet_wrap(~c35_03_var) +
ylab(label = NULL) + xlab(label = NULL) +
scale_color_viridis_d(begin = .0, end = .8, option = 'viridis',direction = 1) +
geom_text_repel(size = 4, nudge_y = .01) +
theme(plot.caption = element_text(hjust = 0),
legend.position = 'top',
legend.title = element_blank(),
axis.text.x = element_text(size = 10,
face = "bold"), # Tamaño de letra para el eje x
axis.text.y = element_text(size = 10),
legend.text = element_text(size = 12),
strip.text = element_text(size = 12)) +
ggtitle(labels_list[["c05_03"]],
subtitle = 'Porcentaje que responde...') +
labs(caption = 'Fuente: ELSOC 2016-2023.\nNota: Se consideran observaciones de individuos sin atrición entre olas. N=12.749 (2.076 individuos).')
t
graficos_cruces[[length(graficos_cruces)+1]] <- t
names(graficos_cruces)[length(graficos_cruces)] <- "c35_03_c05_03"
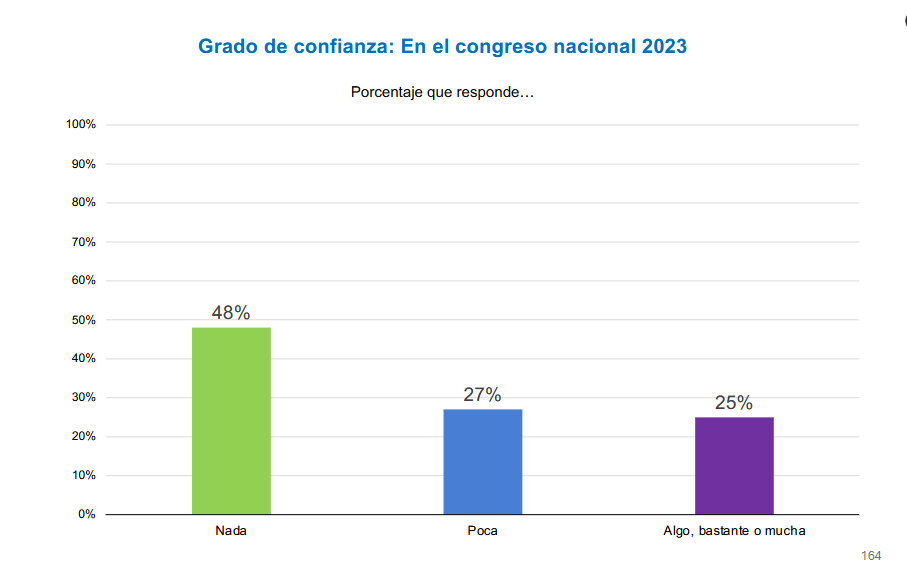
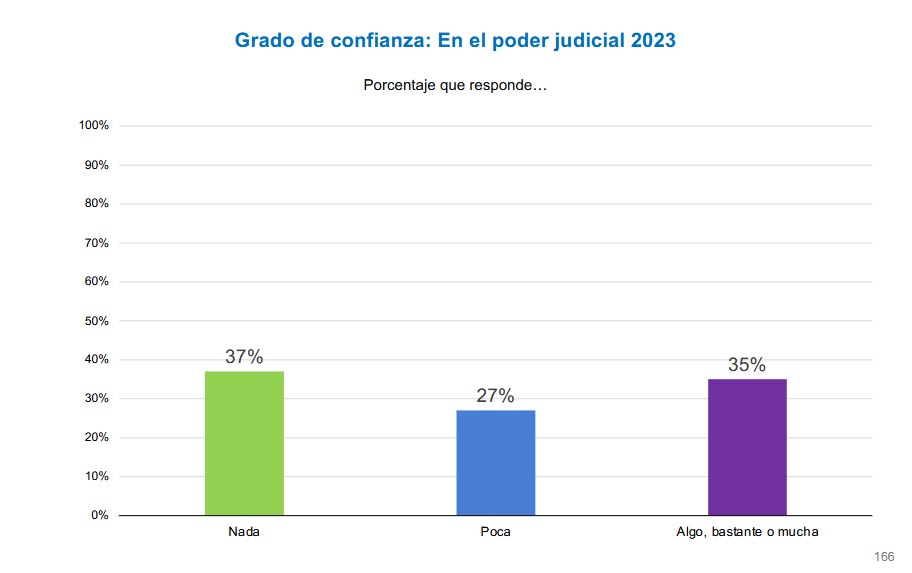
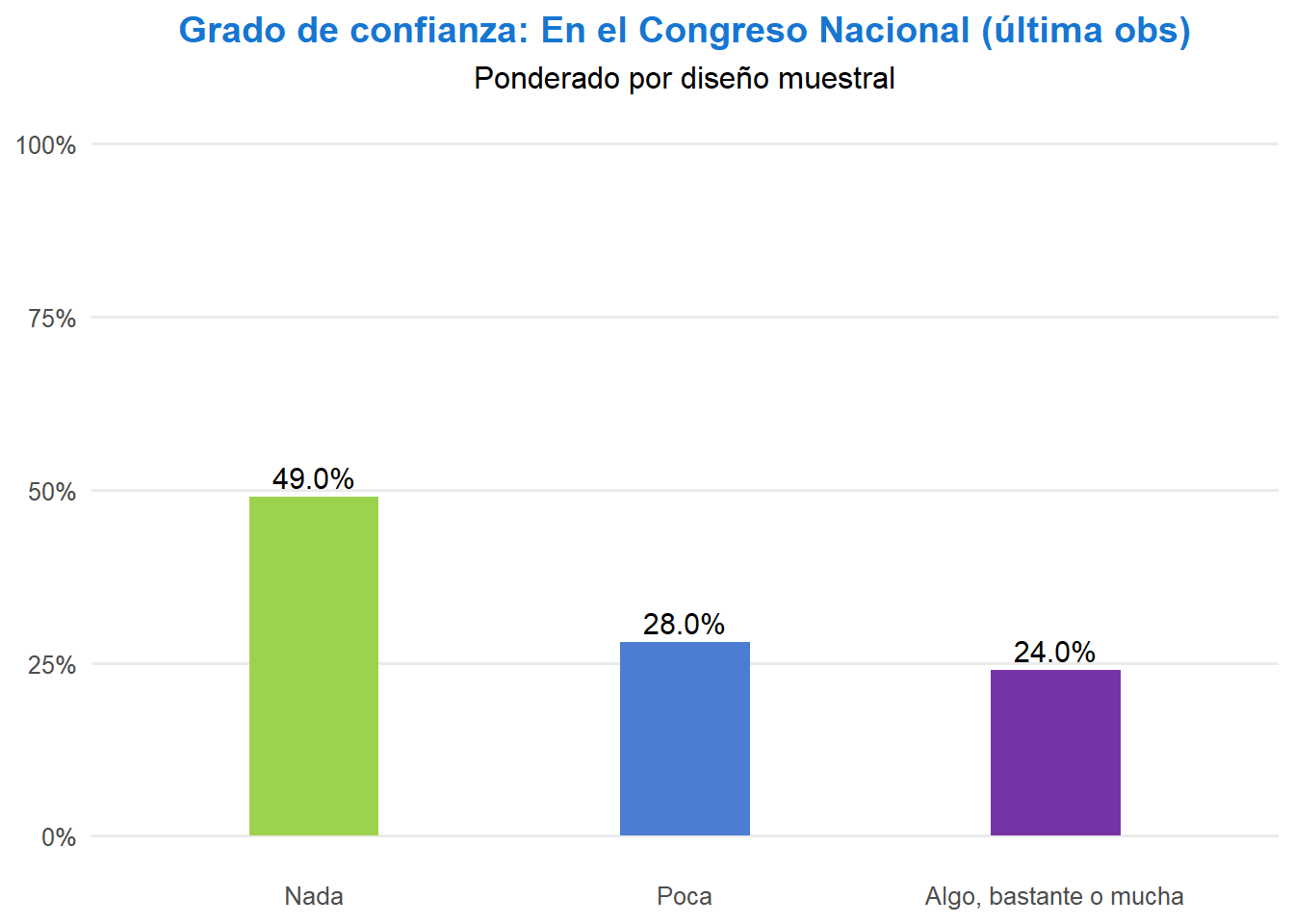
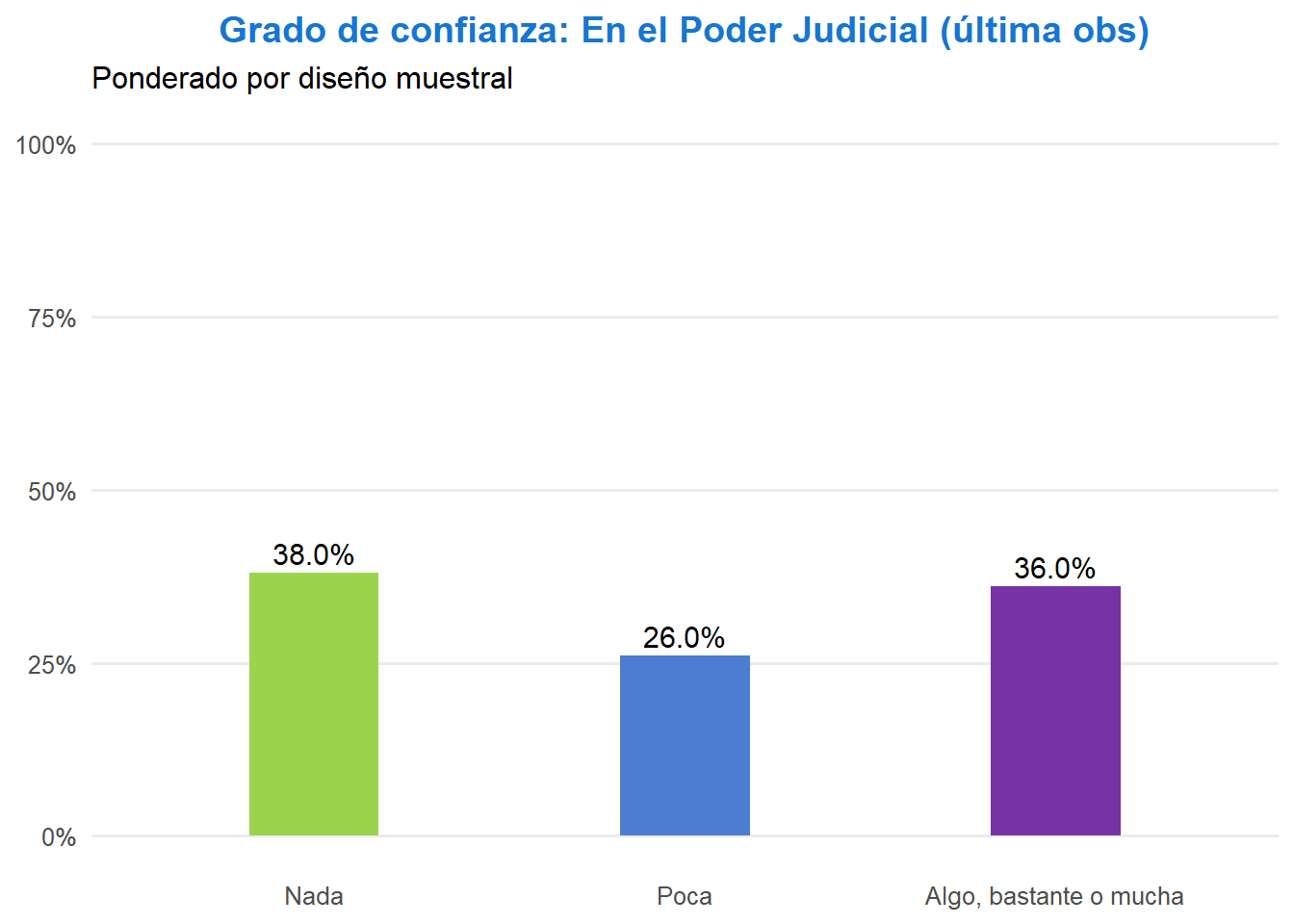
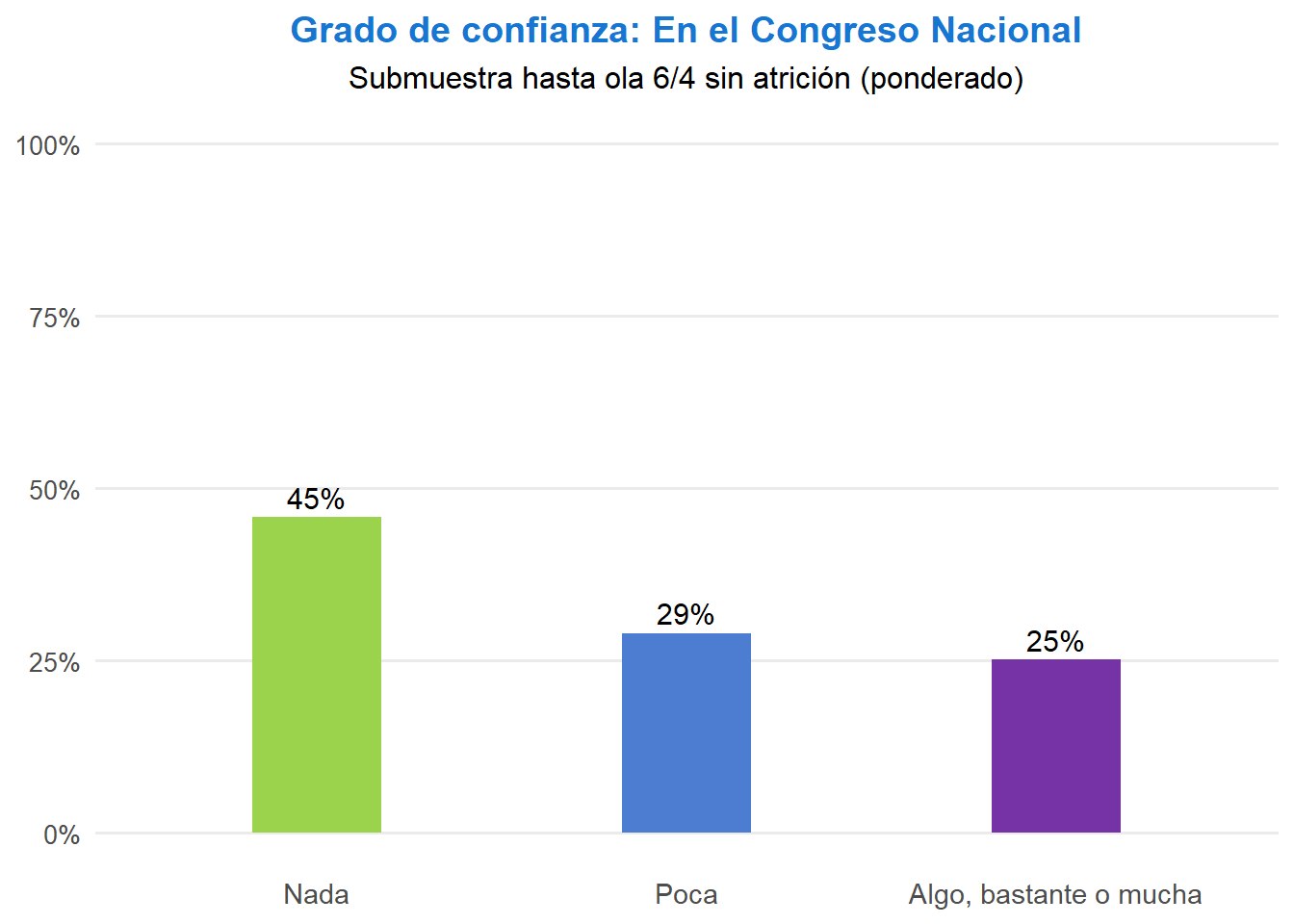
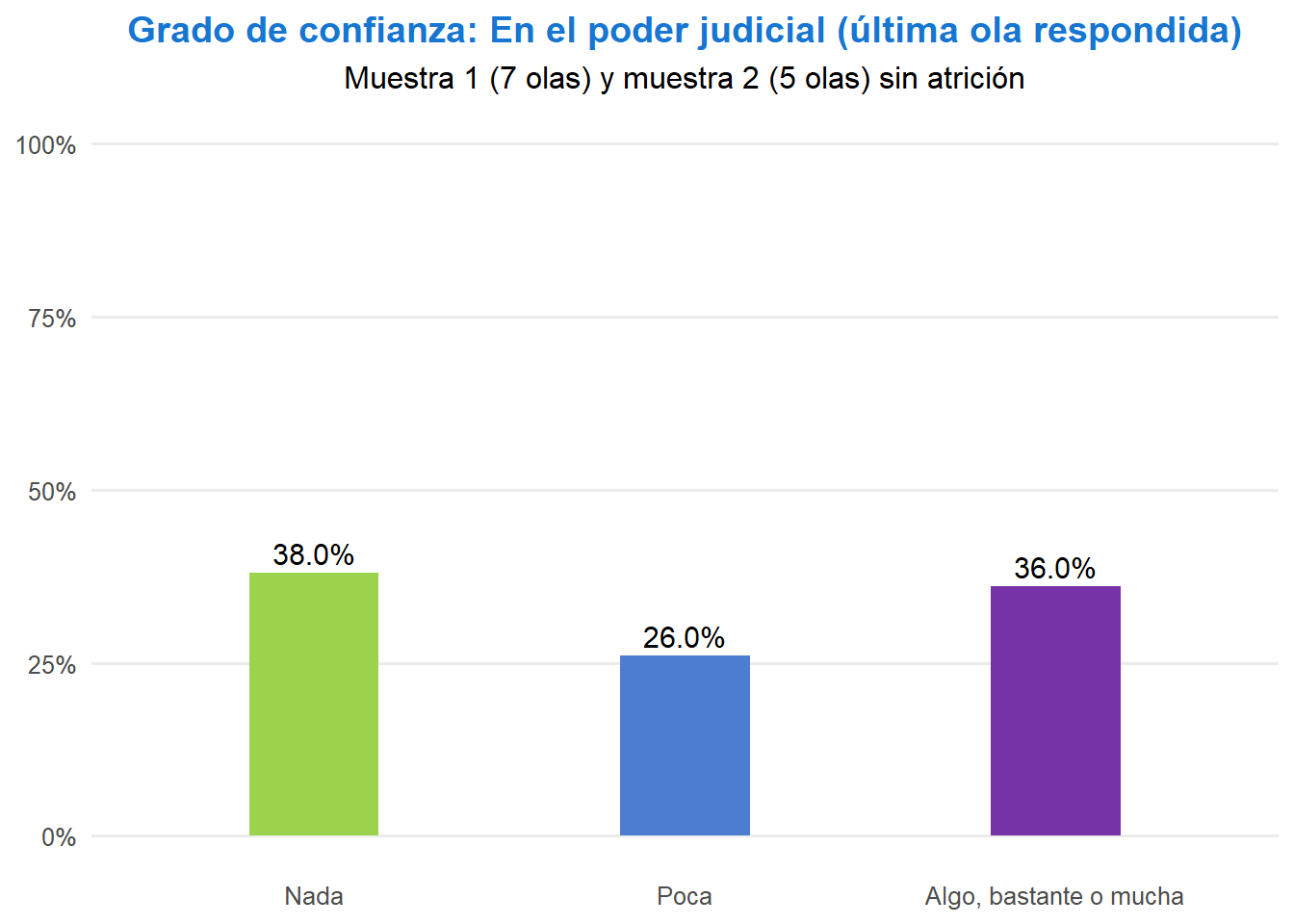
# Poder judicial: se replica el mismo filtro y conteo usados en index.qmd
t <- ell_23 %>%
filter(tipo_atricion == 1) %>%
filter(!is.na(ola)) %>%
group_by(idencuesta) %>%
slice_max(order_by = ola, n = 1, with_ties = FALSE) %>%
ungroup() %>%
drop_na(c05_05) %>%
mutate(conf_judicial = case_when(
c05_05 == 1 ~ "Nada",
c05_05 == 2 ~ "Poca",
c05_05 %in% 3:5 ~ "Algo, bastante o mucha",
TRUE ~ NA_character_
)) %>%
filter(!is.na(conf_judicial)) %>%
count(conf_judicial) %>%
mutate(prop = n / sum(n),
pct_label = paste0(floor(prop * 100), "%"),
conf_judicial = factor(conf_judicial, levels = c("Nada", "Poca", "Algo, bastante o mucha"))) %>%
ggplot(aes(x = conf_judicial, y = prop, fill = conf_judicial, label = pct_label)) +
geom_col(width = 0.35) +
geom_text(vjust = -0.4, size = 4) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
scale_fill_manual(values = c("Nada" = "#9BD44C", "Poca" = "#4D7DD1", "Algo, bastante o mucha" = "#7633A5")) +
labs(title = "Grado de confianza: En el poder judicial (última ola respondida)",
subtitle = "Muestra 1 (7 olas) y muestra 2 (5 olas) sin atrición",
x = NULL,
y = NULL) +
theme_minimal(base_size = 12) +
theme(panel.grid.major.x = element_blank(),
panel.grid.minor = element_blank(),
legend.position = "none",
plot.title = element_text(color = "#1676D2", face = "bold", hjust = 0.5),
axis.text.x = element_text(size = 10),
axis.text.y = element_text(size = 10))
t
graficos_sd[[length(graficos_sd)+1]] <- t
names(graficos_sd)[length(graficos_sd)] <- "c05_05_bar_index"
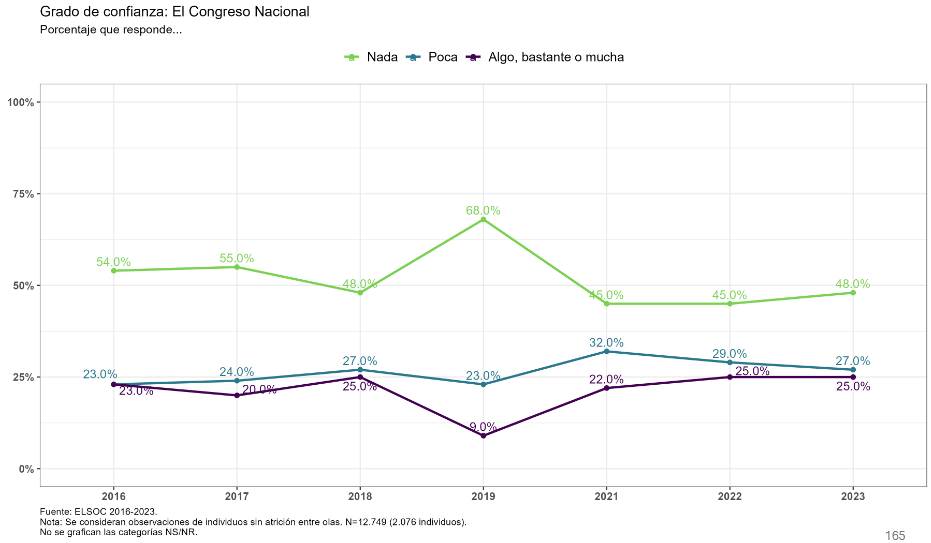
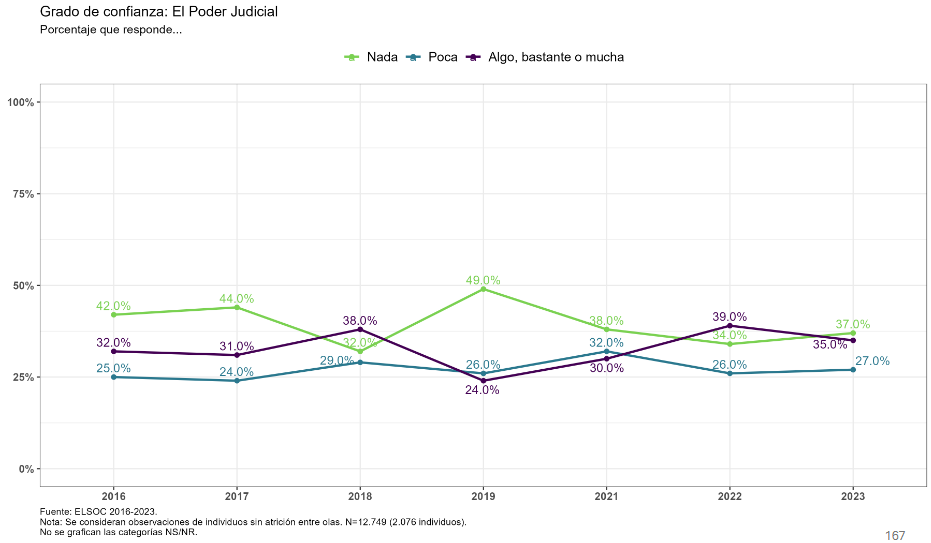
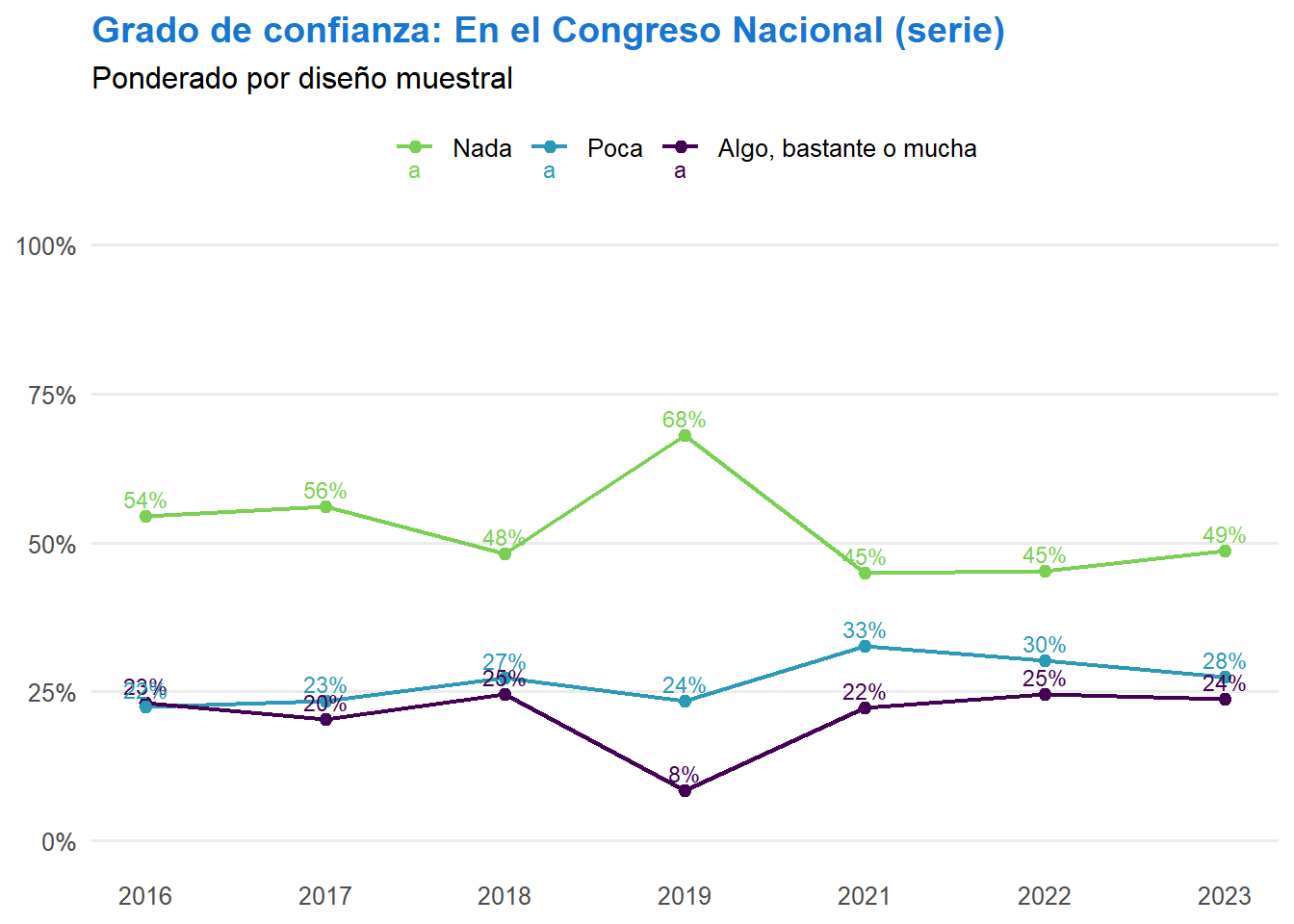
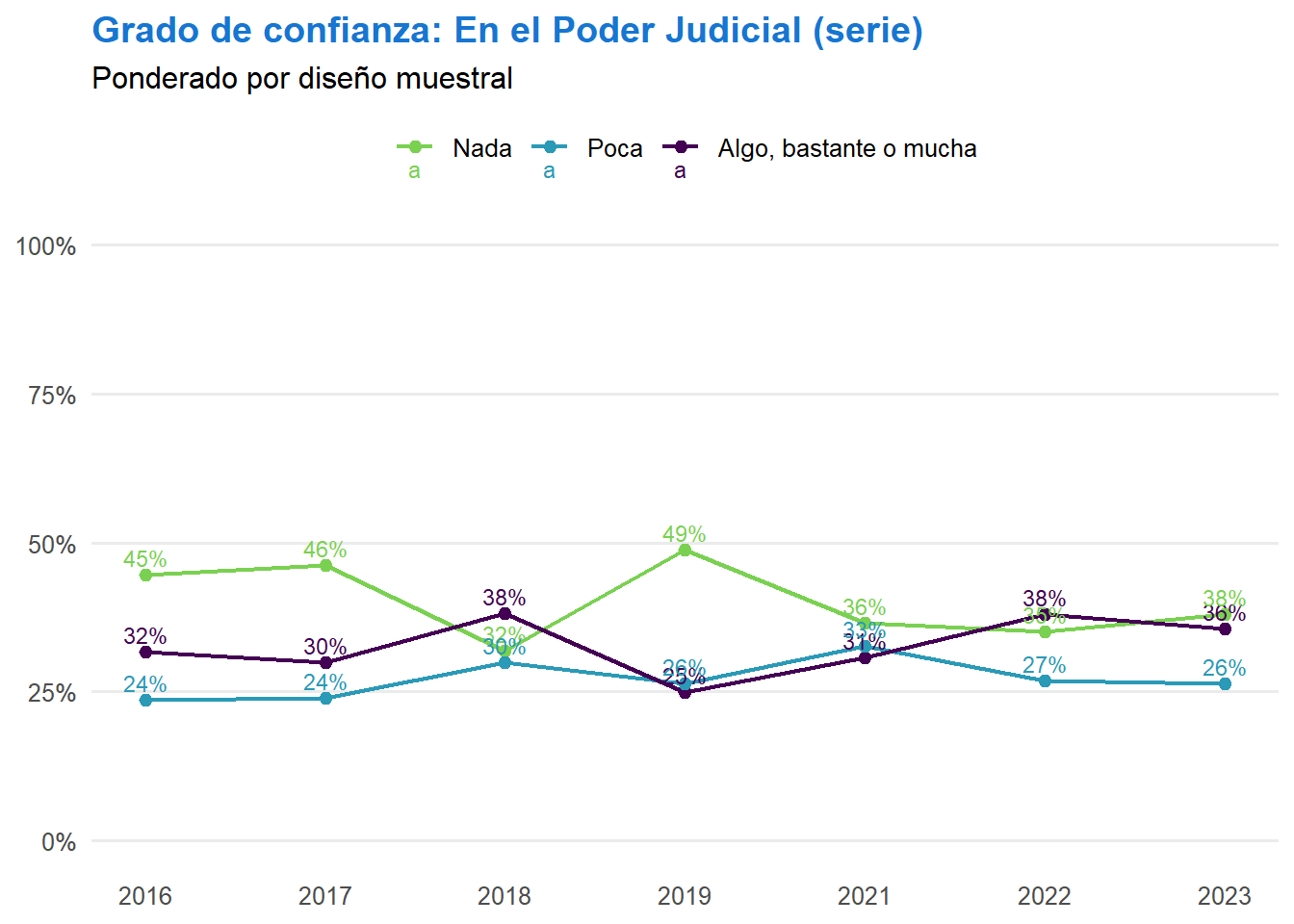
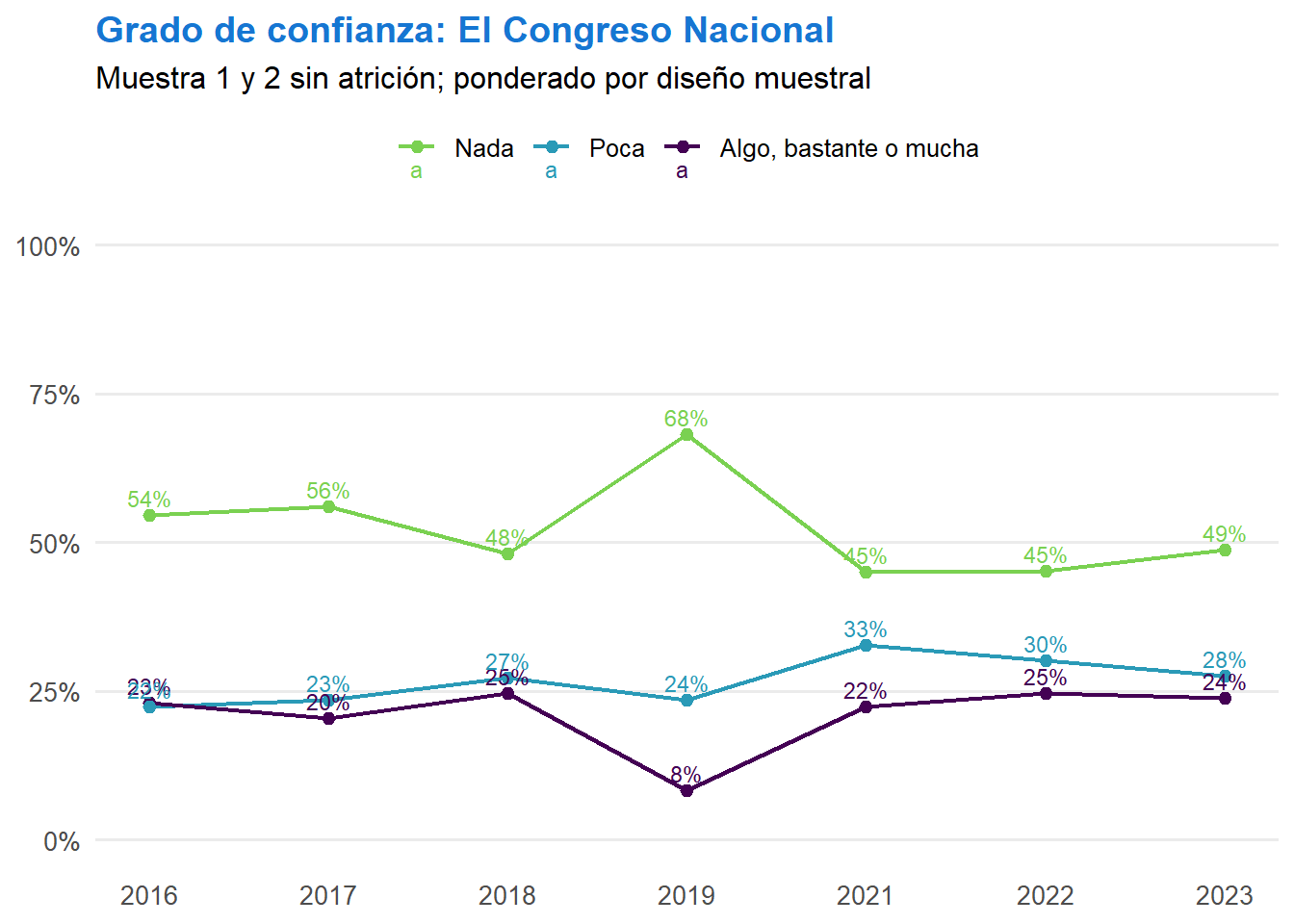
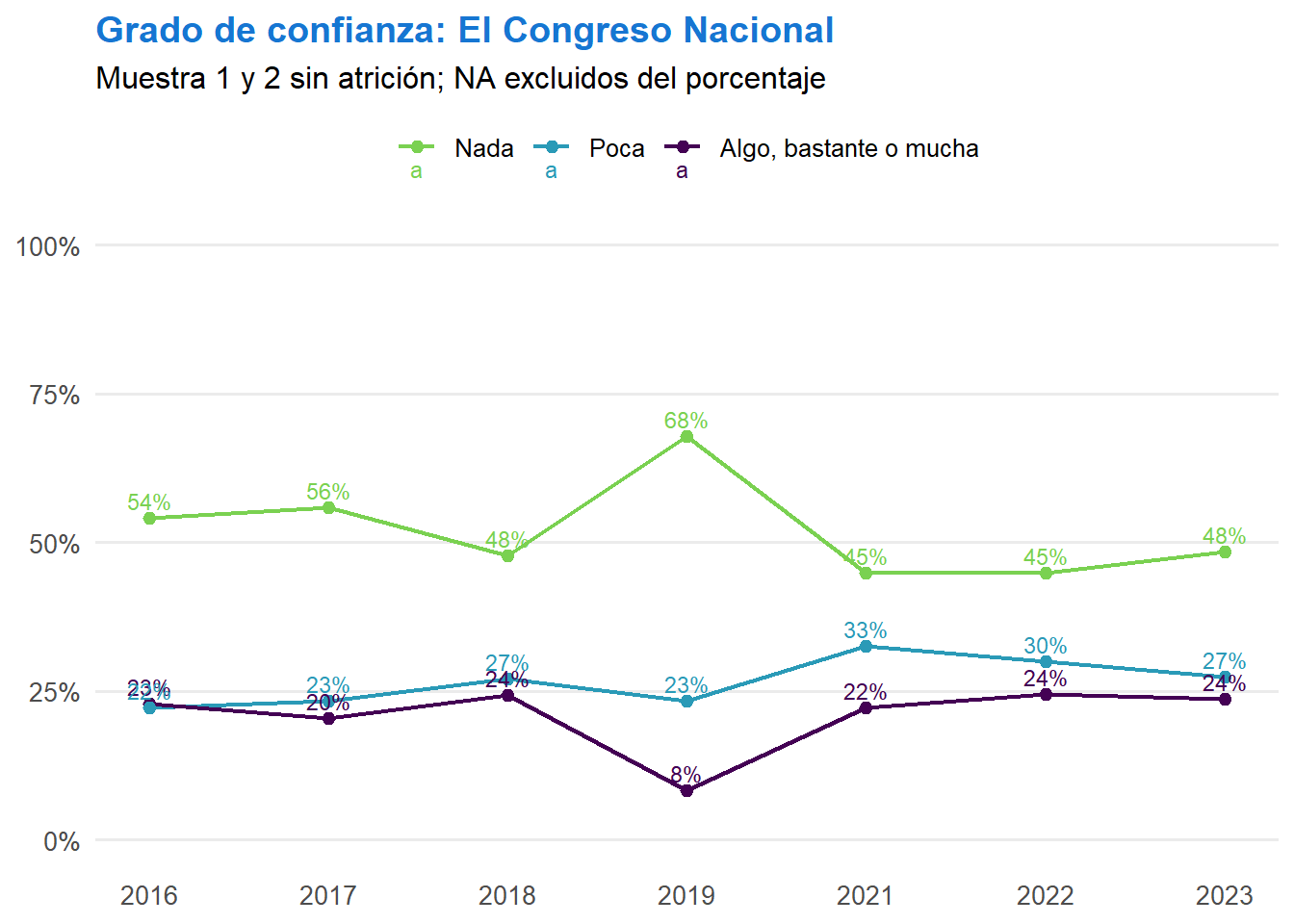
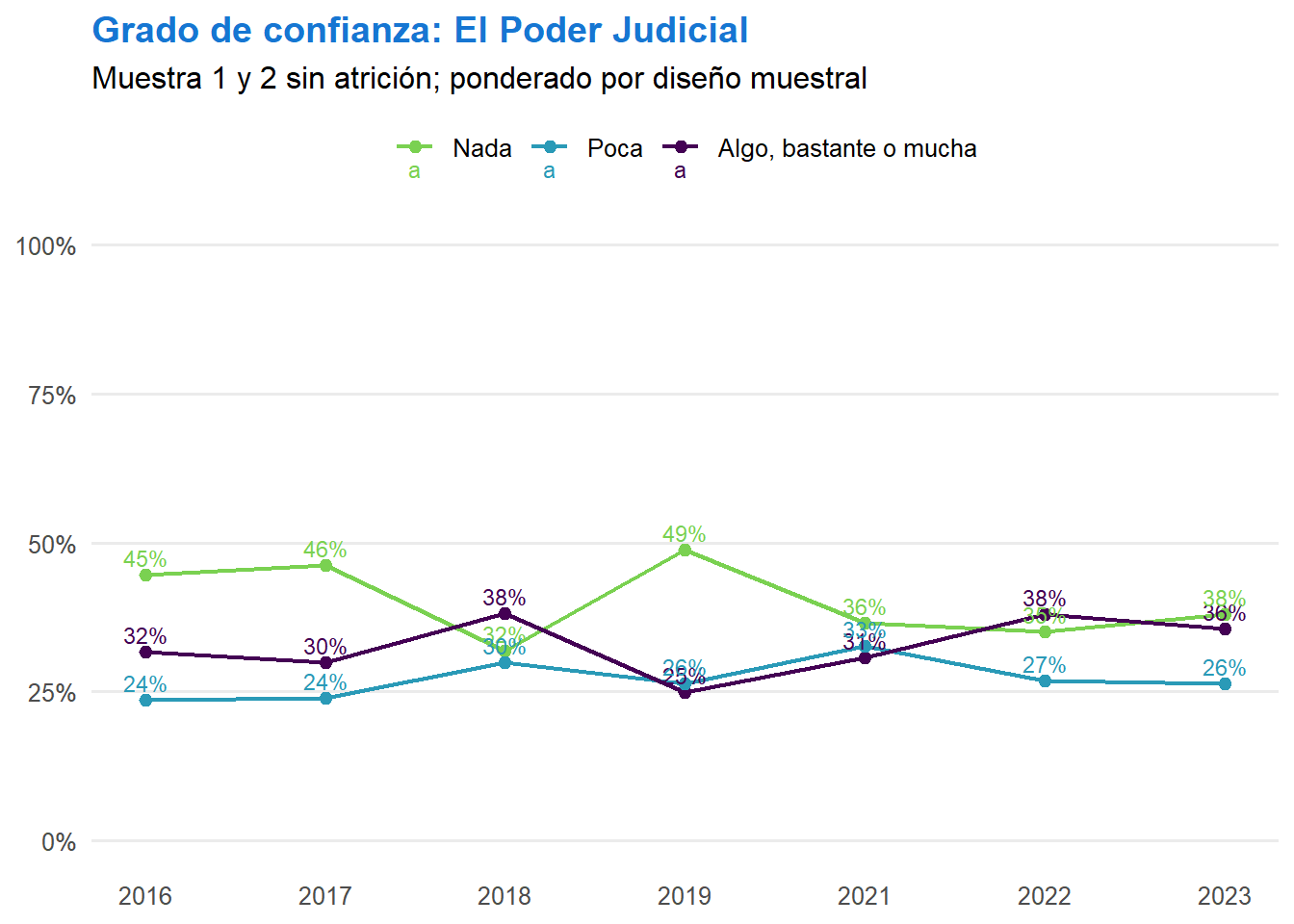
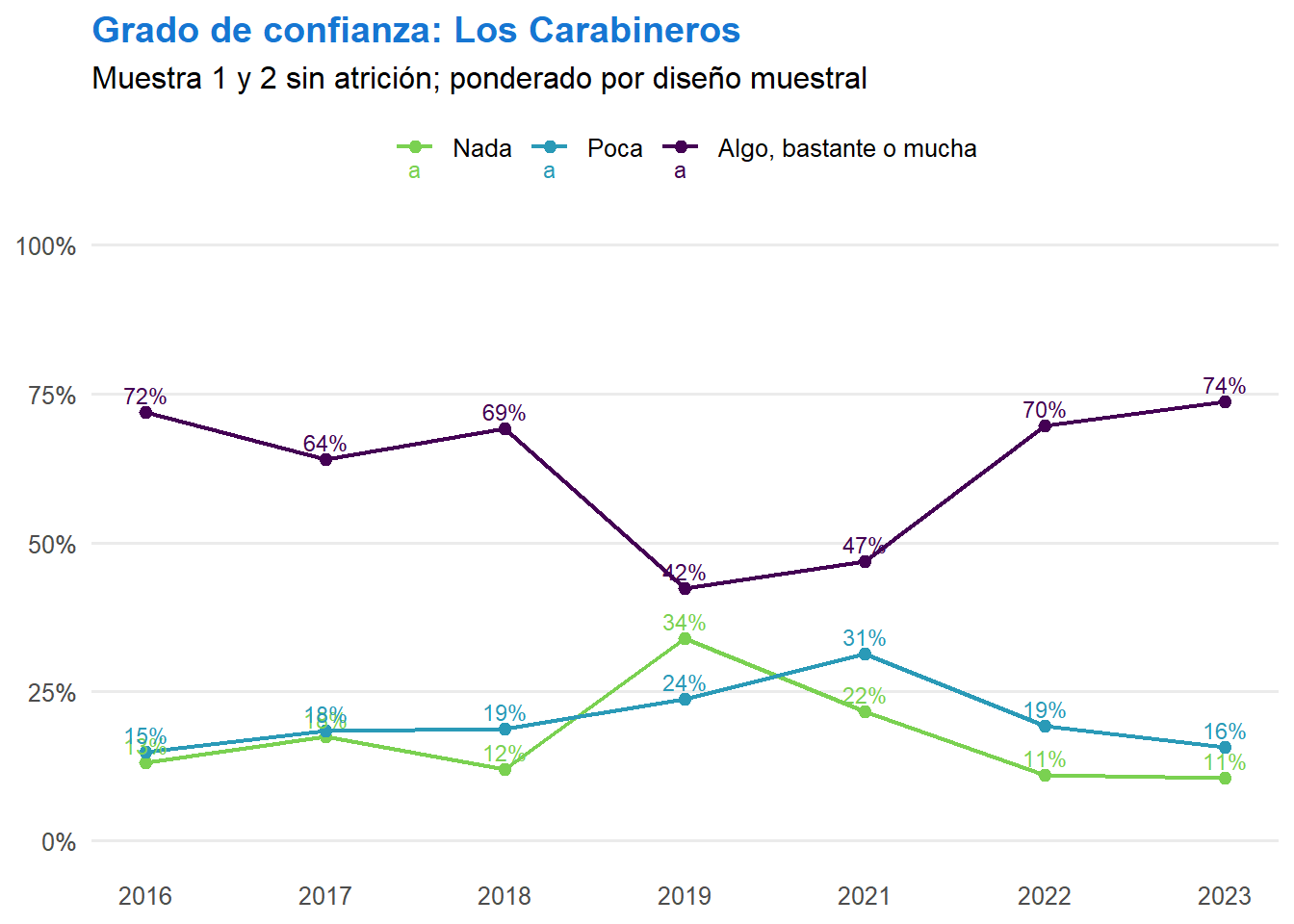
t <- ell_23 %>%
filter(tipo_atricion == 1, !is.na(ola)) %>%
drop_na(c05_05) %>%
mutate(conf_judicial = case_when(
c05_05 == 1 ~ "Nada",
c05_05 == 2 ~ "Poca",
c05_05 %in% 3:5 ~ "Algo, bastante o mucha",
TRUE ~ NA_character_
)) %>%
filter(!is.na(conf_judicial)) %>%
count(ola, conf_judicial) %>%
group_by(ola) %>%
mutate(prop = n / sum(n)) %>%
ungroup() %>%
mutate(conf_judicial = factor(conf_judicial, levels = c("Nada", "Poca", "Algo, bastante o mucha"))) %>%
ggplot(aes(x = ola, y = prop, color = conf_judicial, group = conf_judicial, label = scales::percent(prop, accuracy = 1))) +
geom_line(linewidth = 0.8) +
geom_point(size = 2) +
geom_text(vjust = -0.5, size = 3) +
scale_x_continuous(breaks = 1:7, labels = c("2016", "2017", "2018", "2019", "2021", "2022", "2023")) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
scale_color_manual(values = c("Nada" = "#7AD151", "Poca" = "#2A9AB7", "Algo, bastante o mucha" = "#440154")) +
labs(title = "Grado de confianza: El Poder Judicial",
subtitle = "Muestra 1 y 2 sin atrición; NA excluidos del porcentaje",
x = NULL,
y = NULL,
color = NULL) +
theme_minimal(base_size = 12) +
theme(panel.grid.major.x = element_blank(),
panel.grid.minor = element_blank(),
legend.position = "top",
plot.title = element_text(color = "#1676D2", face = "bold", hjust = 0),
plot.subtitle = element_text(hjust = 0),
axis.text.x = element_text(size = 10),
axis.text.y = element_text(size = 10))
t
graficos[["c05_05_var"]] <- t
# Se guradan los graficos
# Modificacion de graficos
graficos_sd[["frec_cont_nf"]] <- graficos_sd[["frec_cont_nf"]] + scale_color_viridis_d(begin = .0, end = .8,
option = 'viridis',
direction = -1)
graficos_sd[["frec_cont_neg_nf"]] <- graficos_sd[["frec_cont_neg_nf"]] + scale_color_viridis_d(begin = .0, end = .8,
option = 'viridis',
direction = -1)
graficos_sd[["cont_pos_nf"]] <- graficos_sd[["cont_pos_nf"]] + scale_color_viridis_d(begin = .0, end = .8,
option = 'viridis',
direction = -1)
output_dir <- "/Users/gustavoahumada/Dropbox/ELSOC2023/tareas/propuesta_RCS2023/resultados/graficos_lineas/nuevos_graficos2"
#output_dir <- "C:/Users/aigon/Dropbox/ELSOC2023/tareas/propuesta_RCS2023/resultados/graficos_lineas/nuevos_graficos2"
for (i in seq_along(graficos)) {
file_name <- paste(output_dir,paste0(names(graficos)[i],".png"),sep="/")
tryCatch({
ggsave(file_name, graficos[[i]], width = 12, height = 7)
}, error = function(e) {})
}
for (i in seq_along(graficos_sd)) {
file_name <- paste(output_dir,paste0(names(graficos_sd)[i],".png"),sep="/")
tryCatch({
ggsave(file_name, graficos_sd[[i]], width = 10, height = 7)
}, error = function(e) {})
}
for (i in seq_along(graficos_cruces)) {
file_name <- paste(output_dir,paste0(names(graficos_cruces)[i],".png"),sep="/")
tryCatch({
ggsave(file_name, graficos_cruces[[i]], width = 10, height = 7)
}, error = function(e) {})
}